version 0.2 - Mark Pruett
Retrieval Server
The Imprints system is designed to simplify the Samba administrator's task of finding and installing Windows Printer Drivers on a Samba server.
Imprints has four major components: a client tool that retrieves driver packages, a server that provides information on the location of driver packages, a repository for Windows driver packages, and the packages themselves.
This document focuses mainly on the server component, but by necessity it will also discuss some aspects of the other components.
Background
One feature of a Samba server is its ability to download Windows printer drivers to client Windows 95 and Windows NT machines. To do this, the Windows drivers and related files must be installed in designated directories on the Samba server. Acquiring those files and getting them installed in the proper location can be a tedious proposition. The Imprints system is designed to automate this process.
Imprints encompasses the following functions:
- locating a package containing the Windows Driver Files.
- retrieving the package from a repository on either the internet or a local intranet.
- installing the driver package contents, placing the files into the appropriate Samba server directories.
Overview
Figure 1 shows the interactions between Imprints components. The Retrieval Client makes a request to the Retrieval Server. The typical request will be for the locations of a Windows Printer Driver Package. The Retrieval Server responds with the URL of the desired package, if available. At this point, the Retrieval Server's work is done. The client can now download the driver package and install it on the Samba server.
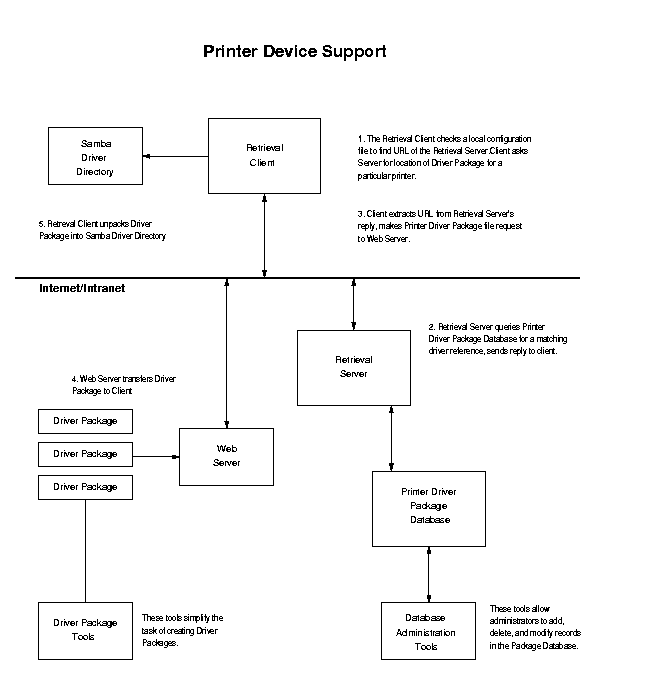
|
|
Figure 1. Imprints Component Interactions |
Design Goals
Imprints needs to work equally well within both internet and intranet environments. In an intranet environment, the administrator must take on the added responsibility of maintaining the server database, the repository of packages, and possibly the creation of packages themselves.
As much as possible, we'll strive to minimize dependencies on other software packages and libraries, as this can add complexity and administrative hassle. We want all the major components of Imprints to be unix-platform independent. Samba is not a linux-only proposition, and neither should Imprints. [Conceptually, Imprints is similar to the apt-get utility used in the Debian Linux distribution. Apt-get provides a server with information on a needed software package, and the server provides a URI that indicates the package's location.]
Overview of the Retrieval Server
It is the job of the server to answer http-based queries for information on the location of Windows driver packages.
The server recognizes a simple query language (it hardly rates as a language), in the form of a command and a set of named parameters. These are provided to the server by the client using the traditional cgi-encoding mechanism.
The most common query is a request for the URL of a package for a specific printer driver package. This query consists of the command, "get-location", and the single named parameter, "printer-name". The server searches its database for a matching printer name; if found, it returns this to the client as an text/plain [reference] response.
Client Data (CGI-encoded):
action=get-printer-info&printer-name=xServer Response:
# Imprints server response printer_name\tcanonical_name\tlocation\tpackage_name 20\t20\t35\t20 HP4050TN\tHP Laserjet 4050TN\thttp://somedomain.com/hp4050tn.package\thp4050tn.packageThe printer_name should be the exact name passed by the client. The canonical_name is the "preferred name" of the printer model. The same printer may be identified with slightly different model name spellings. Finally, the database provides a location, the URL where the package is located, and the package_name itself.
[A note about server response formats: Most server responses are in the form of RDB tables. These are tab-delimited text files. The philosophy and use of RDB tables is explained in Rod Manis' book, "Unix Relational Database Management", available from Amazon and elsewhere. A white paper also explains their use (It's available in PDF format here. . A freely available set of tools (written in perl) for manipulating RDB tables is available at ftp://ftp.rand.org/pub/RDB-hobbs/.
RDB table formats always begin with an optional set of comment lines, always starting with the "#" character in the first column. This is followed by a Field Names line. This, and all subsequent lines, are tab-separated. The Field Names line contains the names of each relational table field. This line is followed immediately by the Field Types line. This line provides information about the type of field (numeric or text), and a suggested format length that can be used when outputting data for people to read. The Field Types line is followed by 0 or more Data lines. these are the actual table table, with fields appearing in the same order as was described in the Field Names line.] The client program uses the location and package name information to retrieve the actual package from the internet and install it for use by the Samba server. The actual package does not need to reside on the same server as the retrieval database.
The client can also send an optional region-code parameter. This code indicates a preferred geographic location for the desired package. If the package is available from several sites around the world, the region-code lets the client select the closest site. The server will attempt to honor the region-code request if possible.
Location-Code Listings
The server will also return a list of location-codes and their descriptions. The client command for this is:
action=get-geographyThis returns an RDB table similar to this:
location_code\tlocation_desc 8N\t25 0\tUnited States 1\tCanada ...etc.Error Responses
If the Retrieval Server is unable to fulfill a request, it will return and error response in the form of an RDB table. The table will always contain two fields: error_code and error_desc. The client can determine that an error has occurred by the simple existence of either of these fields in a response.
Back End Database
As much as possible, the Imprints Retrieval Server will be independent of any particular database. The database schema is simple, and it seems unlikely that the size of data tables will ever grow very large, as this is constrained by the number of printer models that are available.
The first implementation will abstract data access into a simple subroutine libraries. The actual database used to store printer information is not final, but I'm leaning toward simple RDB tables for their portability and ease-of-use.
Regardless of the initial database implementation, the Retrieval Server will be designed to make switching to other database engines as painless as possible.
Comments?
This is a preliminary document, and feedback is welcomed and encouraged. The Imprints Forum on Source Forge is the best place to provide feedback.